


Міжнародна група дослідників, до якої увійшла Шира Файгенбаум-Головін, доцент кафедри математики в Університеті Дьюка, об'єднала штучний інтелект, статистичне моделювання та лінгвістичний аналіз для вирішення одного із найактуальніших питань у біблійних дослідженнях: ідентифікації авторів. Дослідження опубліковано у журналі PLOS One.
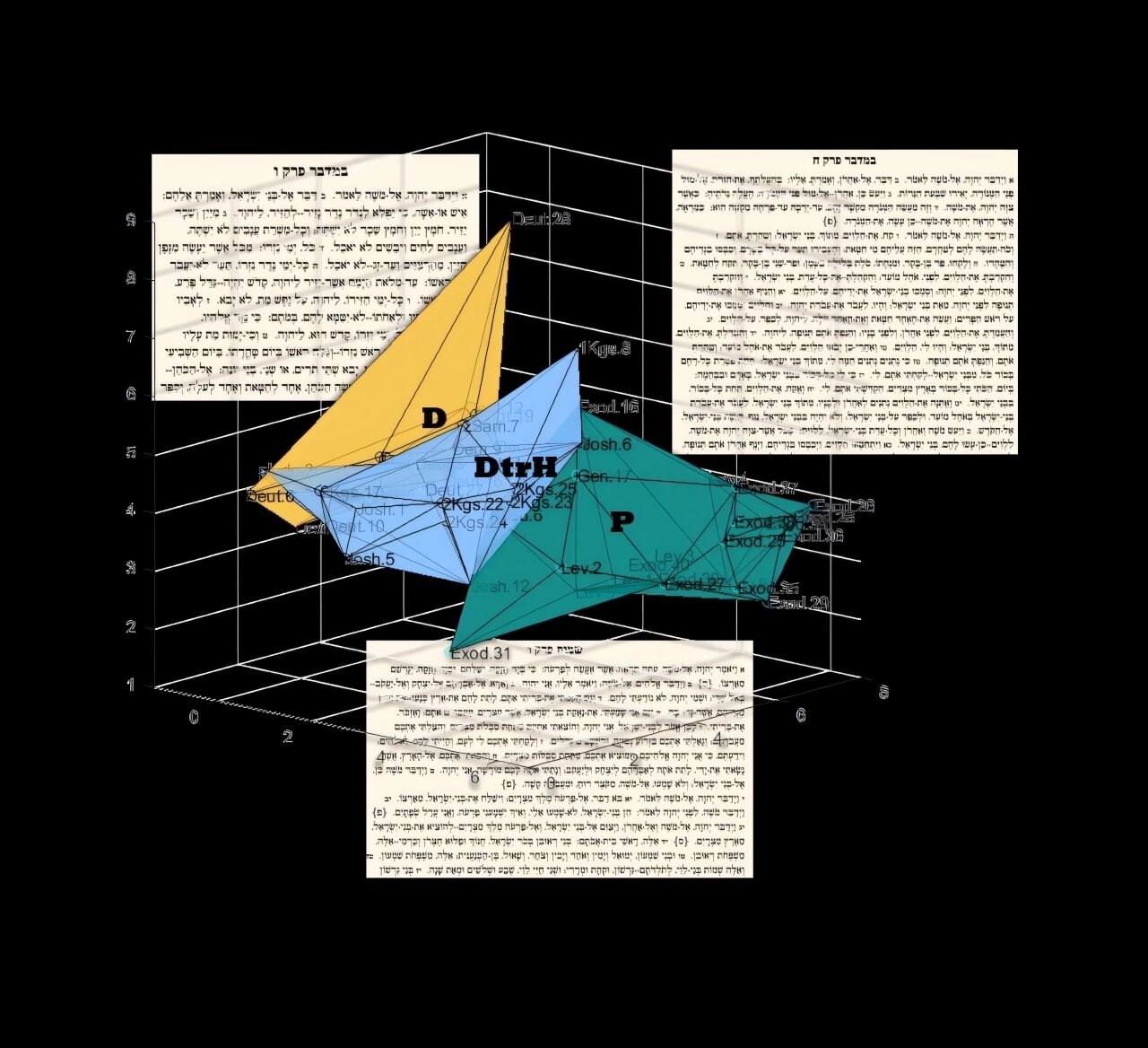
Проаналізувавши тонкі відмінності у використанні слів у різних текстах, команда змогла виділити три окремі традиції переписувачів (стилі письма), що охоплюють перші дев'ять книг єврейської Біблії, відомі як Еннеатеух.
Використовуючи ту ж статистичну модель на основі ІІ, команда змогла визначити найімовірніше авторство інших розділів Біблії. Що ще краще, модель також пояснила, як вона дійшла своїх висновків.
Але як сюди потрапив математик?
У 2010 році Файгенбаум-Головін почала співпрацювати з Ізраїлем Фінкельштейном, керівником Школи археології та морських культур Хайфського університету, використовуючи математичні та статистичні інструменти для визначення авторства написів, виявлених на фрагментах кераміки, що датуються 600 роком до н. фрагмент. Їхні відкриття були опубліковані на першій сторінці The New York Times.
"Ми дійшли висновку, що знахідки в цих написах можуть дати цінні підказки для датування текстів Старого Завіту" , - сказала Файгенбаум-Головін. Саме тоді ми почали збирати нашу нинішню команду, яка могла б допомогти нам проаналізувати ці біблійні тексти.
Міждисциплінарне починання складалося з двох частин.
По-перше, команда Файгенбаум-Головіна і Фінкельштейна - Алон Кіпніс (Університет Райхмана), Аксель Бюлер (Протестантський факультет теології Парижа), Елі Пясецький (Тель-Авівський університет) і Томас Ромер (Колеж де Франс) - складалася з археологів і спеціалісти з інформатики. Команда використала нову статистичну модель на основі ІІ для аналізу мовних моделей у трьох основних розділах Біблії. Вони вивчили перші п'ять книг Біблії: Повторення Закону, так звану Повторення Закону від Ісуса Навина до Царств і священні писання в Торі.
Результати показали, що Повторення Закону та історичні книги більше схожі одна на одну, ніж на інші священні тексти, що вже є консенсусом серед біблеїстів.
"Ми виявили, що кожна група авторів має свій стиль — що дивно, навіть щодо простих і поширених слів, таких як "ні", "який" чи "король". Наш метод точно визначає ці відмінності" , — сказав Ремер.
Для перевірки моделі команда обрала 50 розділів із перших дев'яти книг Біблії, кожну з яких уже було віднесено біблеїстами до одного зі стилів листа, згаданих вище.
"Модель порівняла розділи і запропонувала кількісну формулу для віднесення кожного розділу до одного з трьох стилів листа" , - сказала Файгенбаум-Головін.
У другій частині дослідження команда застосувала свою модель до розділів Біблії, авторство яких викликало спекотніші суперечки. Порівнюючи ці розділи з кожним із трьох стилів письма, модель змогла визначити, яка група авторів із більшою ймовірністю їх написала.
"Однією з головних переваг методу є його здатність пояснювати результати аналізу, тобто вказувати слова або фрази, які призвели до віднесення цього розділу до певного стилю листа ", - сказав Кіпніс.
Оскільки текст Біблії багаторазово редагувався і перевидувався, команда зіткнулася з великими труднощами під час пошуку фрагментів, що зберегли початкові формулювання та мову.
Після виявлення ці біблійні тексти часто були дуже короткими — іноді лише кілька віршів — що робило більшість стандартних статистичних методів та традиційне машинне навчання непридатними для їхнього аналізу. Їм довелося розробити індивідуальний підхід, який міг би обробляти такі обмежені дані.
Обмежені дані часто спричиняють побоювання неточності.
"Ми витратили багато часу, переконуючи себе, що отримані нами результати - не просто сміття" , - сказала Файгенбаум-Головін. «Ми мали бути абсолютно впевненими у статистичній значущості».
Щоб оминути цю проблему, замість використання традиційного машинного навчання, потребує великої кількості навчальних даних, дослідники використовували простий і прямий метод. Вони порівняли шаблони речень та частоту появи певних слів або коренів слів (лем) у різних текстах, щоб побачити, чи були вони написані однією і тією ж групою авторів.
Дивовижна знахідка?
Команда виявила, що хоча два розділи Розповіді про Ковчег у Книгах Царств присвячені одній і тій же темі і іноді розглядаються як частини єдиної оповіді, текст в 1-й Книзі Царств не збігається з жодним з трьох корпусів, тоді як глава у 2-й Книзі Царств демонструє подібність до девиць.
Заглядаючи наперед, Файгенбаум-Головін сказала, що той самий метод може бути використаний і для інших історичних документів.
«Якщо ви дивитеся на фрагменти документів, щоб дізнатися, чи були вони написані, наприклад, Авраамом Лінкольном, цей метод може допомогти визначити, чи вони є справжніми, чи просто підробкою». "Дослідження вводить нову парадигму аналізу стародавніх текстів" , - резюмувала Фінкельштейн.
Файгенбаум-Головін та її команда тепер вивчають можливість використання тієї ж методології для відкриття нових відкриттів про інші давні тексти, такі як сувої Мертвого моря.













